Updated June 8th, 2017. This post was introduced to the Reddit /r/cpp soon after I posted and immediately got a feedback saying “both semantically wrong as well as poorly optimized” which is quite true. 🙂 So I’d like to recommend visiting the Reddit link and consider the comments before preceding or even better, refer to the better example introduced here.
Let’s talk about prime numbers. As an application/system software developer, it’s not often to deal with prime numbers in daily working environments. For me, I came across it while solving the Project Euler’s questions.
There’re a lot of good reads on the net describing what prime numbers are, how to get the numbers. So instead of a basic introduction, I’d like to talk about few tricks which can improve the performance of getting prime numbers.
Let’s first talk about the very basic approach to get prime numbers to compare with optimized version later.
You can check whether it’s a prime number or not when a number is given by following:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| bool isPrime(unsigned long num) | |
| { | |
| if (num == 2) | |
| return true; | |
| if (num <= 1 || num % 2 == 0) // 0, 1, and all even numbers | |
| return false; | |
| for (unsigned long x = 3; x*x <= num; x += 2) { | |
| if (num % x == 0) | |
| return false; | |
| } | |
| return true; | |
| } |
You’ll also get the Nth prime number based on the isPrime() function above by incrementing the counter when it returns true.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| unsigned long get_nth_prime_without_sieve(unsigned long n) { | |
| if (n == 0) return 0; | |
| if (n == 1) return 2; | |
| unsigned long prime_num = 3; | |
| unsigned long local_n = 2; // 2th prime number is 3 | |
| while (local_n != n) { | |
| // check next prime number candidate | |
| prime_num += 2; // 3,5,7,9… check only odd numbers | |
| if (isPrime(prime_num) == true) { | |
| local_n++; | |
| } | |
| } | |
| return prime_num; | |
| } |
It’s self-descriptive and easy.
Can we improve the performance? Sure! There’s a ‘Sieve of Eratosthenes‘ algorithm, and basically, it does pre-calculate all the non-prime numbers when it found a new prime number by removing all multiples.
Here’s the implementation of the algorithm and its example.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| /// snippet from | |
| /// http://www.geeksforgeeks.org/sieve-of-eratosthenes/ | |
| /// | |
| std::vector<bool> SieveOfEratosthenes(unsigned long less) | |
| { | |
| // Create a boolean array "prime[0..n]" and initialize | |
| // all entries it as true. A value in prime[i] will | |
| // finally be false if i is Not a prime, else true. | |
| vector<bool> prime(less + 1); | |
| std::fill(begin(prime), end(prime), true); | |
| for (unsigned long p = 2; p*p <= less; p++) | |
| { | |
| // If prime[p] is not changed, then it is a prime | |
| if (prime[p] == true) | |
| { | |
| // Update all multiples of p | |
| for (unsigned long i = p * 2; i <= less; i += p) | |
| prime[i] = false; | |
| } | |
| } | |
| return prime; | |
| // Print all prime numbers | |
| //for (unsigned long p = 2; p <= less; p++) | |
| // if (prime[p] == true) | |
| // cout << p << " "; | |
| } | |
| unsigned long get_nth_prime_with_basic_sieve(unsigned long n) { | |
| unsigned long precompute_max_count = 100000; | |
| do | |
| { | |
| if (precompute_max_count >= std::numeric_limits<unsigned long>::max()) | |
| break; | |
| auto prime = SieveOfEratosthenes(precompute_max_count); | |
| // how manay 'true' exist? | |
| unsigned long primes_length = std::count(std::begin(prime) + 2, std::end(prime), true); | |
| if (primes_length < n) { | |
| precompute_max_count *= 2; // double the limit & try again | |
| continue; | |
| } | |
| // get index nth true locates | |
| unsigned long nth = 0; | |
| // from prime[2] – (prime[0] and prime[1] are true, but not prime numbers), | |
| // if n is equal to the summed up prime numbers, then return the location. | |
| auto it = std::find_if(begin(prime) + 2, end(prime), [nth, n](bool e) mutable { | |
| if (e) { // find the true elements | |
| nth++; // and increment the count | |
| if (nth == n) // and we found Nth number, | |
| return true; | |
| } | |
| return false; | |
| }); | |
| // get the value of found index points to. | |
| auto d = std::distance(begin(prime), it); | |
| return d; | |
| } while (true); | |
| return 0; | |
| } |
And Lastly, can we improve the Sieve of Eratosthenes algorithm better? Yeah, it’s possible. I first saw the optimized implementation from one of the answers here: http://qa.geeksforgeeks.org/3090/how-to-find-nth-prime-number It’s tricky to understand at first glance in fact. So that I rewrote a little bit and here’s the result:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <memory> | |
| // note1. 홀수 n이 주어졌을 때, n이 몇 번째 홀수인지 알아내려면 (n – 3) >> 1 한다. | |
| unsigned long get_nth_prime_with_optimized_sieve(unsigned long n) { | |
| unsigned long precompute_max_count = 200000; | |
| // prime number를 체크하기 위해 우선 대상이 될 모든 odd number들을 담을 배열을 만든다. | |
| vector<bool> odd_numbers_divisible(precompute_max_count/2); // odd numers | |
| // n개의 prime number들이 담길 array를 만든다. | |
| auto primes = std::make_unique<unsigned long[]>(n); | |
| // 3부터 모든 odd numbers에 대하여, | |
| for (unsigned int i = 3; i <= std::sqrt(precompute_max_count); i += 2) // 3, 5, 7, 9, 11, 13….9257 | |
| { | |
| auto i_th = (i – 3) >> 1; // i_th는 i라는 odd#가 몇 번째 odd number인지 구한다. | |
| if (odd_numbers_divisible[i_th] == false) // divide 할 수 없는 prime #찾았다면, | |
| { | |
| // prime number를 찾았다면, loop 돌며 이후 i의 위치마다 모두 prime number가 아니라고 체크해 둔다. | |
| for (unsigned int j = i*i; j < precompute_max_count; j += i) | |
| { | |
| // j는 이미 다른 수의 제곱이고 3부터 증가하는 홀수(3,5,6,7…) i 를 더한 값이므로, | |
| // j는 prime#가 아니다. | |
| if (j & 1) // odd인 경우에만. even인 경우는 아예 prime #가 아니다. | |
| { | |
| // 3번째 odd#는 9, (9-3) >> 1 하면 3 | |
| // 6번째 odd#는 15, (15-3) >> 1하면 6 | |
| // y는 j라는 홀수가 몇 번째 홀수인지를 index를 구한다. | |
| auto y = (j – 3) >> 1; | |
| // y번째 odd#는 prime#가 아니다. divide 할 수 있다. | |
| odd_numbers_divisible[y] = true; | |
| } | |
| } | |
| } | |
| } | |
| unsigned long primes_length = std::count(std::begin(odd_numbers_divisible), std::end(odd_numbers_divisible), false) + 1; | |
| // odd_numbers_divisible는 3부터 체크하므로 prime number인 2를 하나 더 함 | |
| if (primes_length < n) { | |
| return 0; | |
| } | |
| // 첫번째 prime #는 2다. | |
| primes[0] = 2; | |
| unsigned int cnt = 1; | |
| for (unsigned int i = 0; 2 * i < precompute_max_count && cnt < n; i++) | |
| { | |
| if (odd_numbers_divisible[i] == false) | |
| { | |
| primes[cnt++] = 2 * i + 3; | |
| //cout << 2 * i + 3 << " "; | |
| } | |
| } | |
| //cout << endl; | |
| // [0]에 첫번째 prime이 있으므로 6번째 primn이라면 [6-1] 구해야 한다. | |
| return primes[n – 1]; | |
| } |
Comments are still Koreans and will be translated into English soon. Few tricks used to improve the performance are like following:
#1. Check against odd numbers only from line 26 – if (j & 1
#2. Getting the odd number index when an odd number n is given: (n – 3) >> 1
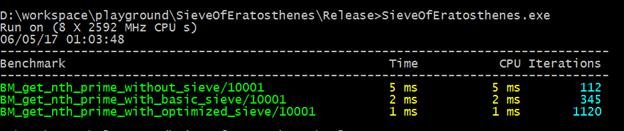
If I changed the unit into ns…

D:\workspace\playground\SieveOfEratosthenes\Release>SieveOfEratosthenes.exe –benchmark_format=json
{
“context”: {
“date”: “06/05/17 01:06:32”,
“num_cpus”: 8,
“mhz_per_cpu”: 2592,
“cpu_scaling_enabled”: false,
“library_build_type”: “release”
},
“benchmarks”: [
{
“name”: “BM_get_nth_prime_without_sieve/10001”,
“iterations”: 160,
“real_time”: 4618235,
“cpu_time”: 4589844,
“time_unit”: “ns”
},
{
“name”: “BM_get_nth_prime_with_basic_sieve/10001”,
“iterations”: 373,
“real_time”: 1854873,
“cpu_time”: 1843164,
“time_unit”: “ns”
},
{
“name”: “BM_get_nth_prime_with_optimized_sieve/10001”,
“iterations”: 1120,
“real_time”: 642190,
“cpu_time”: 655692,
“time_unit”: “ns”
}
]
}
You can access the sample here: https://github.com/heejune/SieveOfEratosthenes
It’ll require the google benchmark and few modifications to correctly link and search headers and libraries to build.
Thanks,
Heejune
